Introduction
심층신경망(Deep Neural Networks)은 딥러닝 시대 이전의 기술들로는 해결할 수 없던 여러 Task들을 성공적으로 수행할 수 있음을 보여주었다. 하지만, 현재 Image Recognition등 많은 problem domain에서 state-of-the-art 성능을 내는 모델들의 구조는 대부분 그 분야의 전문가들이 손수 디자인한 결과이다. 딥러닝 연구자들은 잘 알겠지만, task와 데이터셋이 주어졌을때 어떠한 구조를 사용해야 할지를 결정하는 것은 정말 피곤한 작업이다. 예를 들어, convolutional network를 만들때, hidden layer는 몇개를 쓸 것인지, layer당 filter는 몇개를 쓸 것인지, filter의 size, padding, stride는 어떻게 설정할 것인지, 언제 pooling을 할 것인지 같은 것들은 모델의 구현자가 직접 설정해줘야되는데, 문제는 이러한 design decision들이 좋은지 안좋은지는 모델을 학습시켜보기전까진 모른다는 것이다. 거기다가, 최적의 신경망구조가 딱 하나로 정해져있으면 좋겠지만, 어느 task에서 어느 데이터셋을 쓰느냐에 따라 최적의 네트워크 구조도 달라지기 때문에 한 데이터셋에서 좋은 결과를 냈다고 해서 다른 데이터셋에서도 같은 구조의 모델이 좋은 성능을 보일거라는 보장이 없다. 그리고 (어느정도 깊이가 있는) 인공신경망은 머신러닝 모델들 중에서도 학습속도가 느리기로 악명이 높다. 결국, 최적의 네트워크 구조를 디자인은 하는 일은 시간 겁나 버리는 힘든 일이라는 것이다. Neural Architecture Search (NAS)는 바로 이 힘든 작업을 자동화하여 주어진 task에 가장 최적인 네트워크 구조를 편리하고 빠르게 탐색하는 방법론을 연구하는 분야이다.
Three components
내가 석사과정을 밟고 있는 연구소에서 발표한 다양한 NAS 방법론들을 모아 잘 정리 해놓은 논문이 있다. 이 논문에선 NAS 알고리즘을 세 개의 component로 나누어 설명한다.
-
Search space
Search space는 알고리즘이 탐색을 수행하는 공간을 의미한다. 이 탐색공간에는 candidate operation (convolution, fully-connected, pooling, etc.)의 집합과 그 operation들이 어떻게 연결 되는지, 그리고 총 몇개의 operation이 모여 네트워크를 구성하는지가 정의된다. 그렇기 때문에 이 공간의 모든 원소는 각각 하나의 유효한 네트워크 구조 (valid network configuration)를 나타낸다고 할 수 있겠다. -
Search Strategy
Search strategy는 말 그대로 탐색방법을 의미한다. 탐색공간상의 많은 configuration들 중에서 어떤것이 가장 좋은 configuration인지를 빠르고 효율적으로 찾아낼 수 있는 알고리즘이 좋은 알고리즘이라고 할 수 있다. 탐색방법은 탐색공간을 어떻게 정의하느냐, 목표가 무엇이냐에 따라 random search, reinforcement learning, evolutionary strategy, gradient descent, bayesian optimization 등 여러가지 방법이 있다. 그리고 Search strategy를 디자인 할때는 그것이 주어진 탐색공간의 작은 부분만 탐색하지 않고 대부분을 커버하면서 (exploration) 동시에 탐색공간의 좋은 부분을 빠르게 찾아낼 수 있도록 해야 한다 (exploitation). 보통 이 둘증 하나에 집중하면 다른 하나가 그만큼 외면되는 경향이 있데, 이러한 현상은 exploration-exploitation trade-off라고 하여 탐색 알고리즘을 디자인할때에 잘 고려해야 하는 현상이다. 그렇기 때문에 좋은 search strategy는 exploration과 exploitation을 둘 다 잘 수행할 수 있어야한다. -
Performance Estimation Strategy
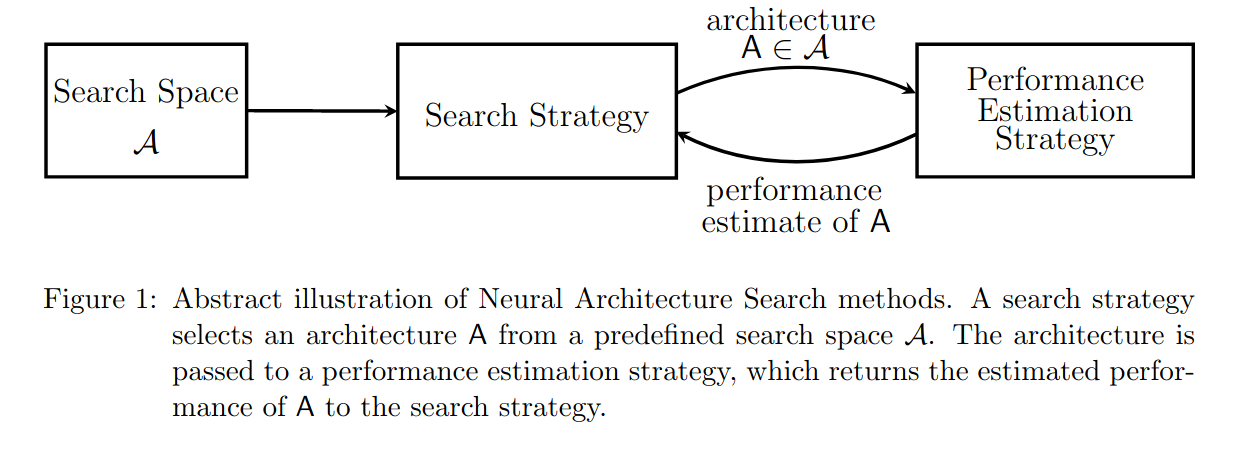
Figure 1 에서 볼 수 있듯이, 보통 NAS는 search strategy가 하나, 혹은 여러개의 후보 configuration을 추출하면 performance estimation strategy를 통해 그것들의 성능을 예측하고, 그 예측치들을 바탕으로 search strategy가 더 좋을 것이라고 생각되는 새로운 configuration들을 추출하는 과정을 최적의 configuration으로 수렴될때까지 반복수행하는 방식으로 이루어진다. 여기서 performance evaluation이 아닌 estimation인 이유는 모든 configuration을 일일히 끝까지 학습시켜 evaluate하면 너무 많은 시간이 소요되기때문이다. 그렇기 때문에 후보 configuration들의 성능을 완전히 학습시키지 않고도 성능을 잘 예측할 수 있는 performance estimation strategy를 개발하는 것이 효율적 NAS 알고리즘을 만드는 중요한 요소라고 할 수 있다.
Examples
NAS에 흥미가 있는 분들은 링크를 걸어 놓았으니 아래에 3개의 대표적인 논문들을 읽어 보길 권한다.
-
NAS with Reinforcement Learning
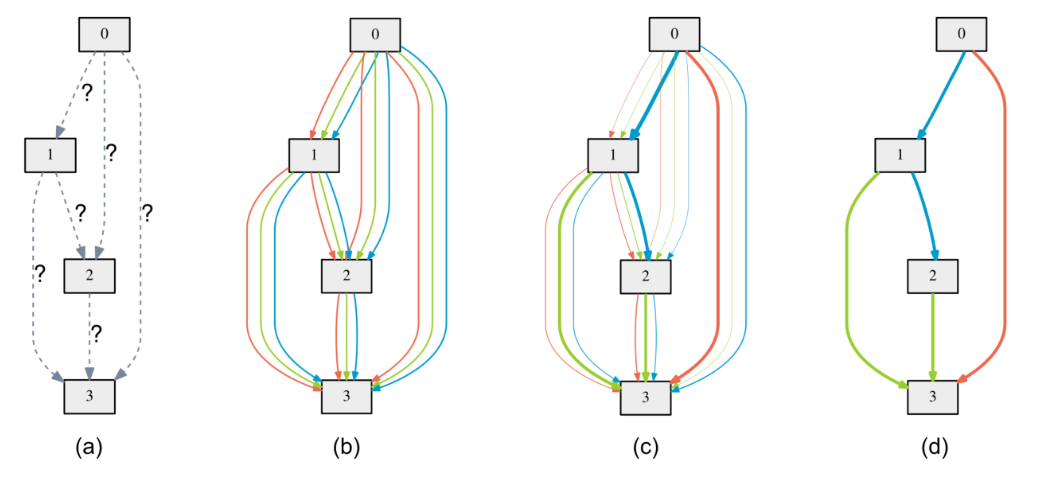
Zoph와 Le의 연구는 처음으로 강화학습을 사용한 NAS 방법론을 제시한 것으로서 NAS의 역사를 논할때 빠지지 않는 중요한 연구이다. 본 연구는 신경망의 구조를 가변길이의 문자열 (variable-length string)으로 나타낼 수 있다는 점에 착안해, 이러한 문자열을 내뱉는 rnn controller (RL의 agent에 해당) 를 만들고, 그것이 출력한 문자열으로 신경망을 만들고 학습하여 얻어진 validation accuracy를 RL의 reward로 보고, controller가 reward를 최대화하는 문자열을 출력하도록 학습을 시켜 NAS를 수행하였다.
-
AmoebaNet
Evolutionary strategy를 사용한 NAS연구도 있다. Real et. al은 정의된 search space로 부터 랜덤하게 샘플링된 네트워크들의 population을 학습시키고, 그 중 validation loss가 가장 낮은 네트워크들의 구조에 random mutation을 주어 학습시키는 작업을 반복해서 최적의 네트워크 구조가 학습될 수 있도록 하였다.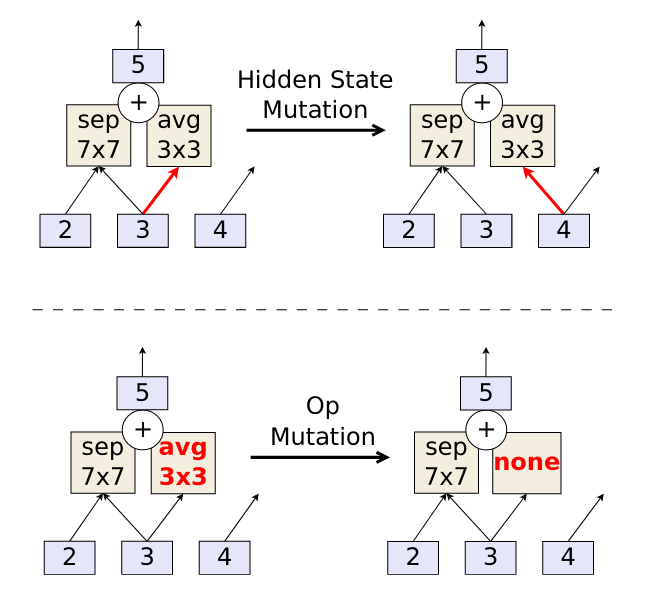
-
Differentiable Architecture Search (DARTS)
DARTS는 처음으로 search space를 미분가능한 형태로 변환시켜 architecture search를 gradient descent를 통하여 수행한 최초의 논문이다. DARTS의 탐색은 위의 방법들보다 훨씬 빠르기 때문에 논문이 공개되었을때 상당히 주목을 받았고, 내 석사논문연구에서도 DARTS를 보완한 알고리즘을 사용하였다. DARTS는 내가 개인적으로 굉장히 흥미롭다고 생각되는 방법이기 때문에 다음 포스팅에서는 DARTS를 리뷰하고 그 수학적 원리를 설명해 보겠다.